Distant Reader Index
Abstract
This posting outlines how I implemented an index to Distant Reader content through the use of Koha and protocol called SRU (Search/Retrieve via URL). Because of this implementation it is easy for me (or just about anybody else) to search the collection for content of interest and create Distant Reader data sets ("study carrels"). TLDNR: Implement a Koha catalog, turn on SRU, patch the SRU server, and write XSL stylesheets.
Introduction
I have cached a collection of about .3 milllion plain text, JSON, PDF, and TEI/XML files. These files are etexts/ebooks or journal articles. Everything dates from Ancient Greece to the present. For the most part, the subject matter lies squarely in Western literature, but there is a fair amount of social science material as well as an abundance of COVID-related articles. Everything is written in English and everything is open access. This is my library.
I wanted to make my library available to a wider audience, and consequently I implemented a traditional library catalog against the collection -- The Distant Reader Catalog. I outlined the implementation of this catalog -- a Koha instance -- in a different posting. The result works very much like a library catalog. Patrons. Libraries. Circulation. Items. MARC records. Etc. But I also desired a machine-readable way to search the catalog and programmatically process the results. Fortunately, Koha suports a standard API called "SRU" (Search/Retrieve via URL) which is intended for exactly this purpose. Thus, this posting outlines how I implemented SRU against my collection of .3 million open access items.
Implementing SRU
SRU is a protocol for querying remote indexes. Like OAI-PMH, it defines a set of standardized name/values pairs to be included in the query of a URL. Unlike OAI-PMH, it is intended for search where OAI-PMH is used for browse and harvest.
Fortunately -- very fortunately -- Koha supports SRU out-of-the-box. All one has to do is turn it on from the Koha administrative interface. Sent from the command line, the following URL ought to return an SRU Explain response outlining the functionality of the underlying server:
http://catalog.distantreader.org:2100/biblios
After reading between the lines of the Explain response, one can then search. Here is a query for the word "love", and it will only return the number of records found. For the sake of readability, carriage returns have been added to the query, and the query is linked to the XML response:
http://catalog.distantreader.org:2100/biblios? version=2.0& operation=searchRetrieve& query=love
This URL will not only search but also retrieve (4) records in the given MARCXML schema:
http://catalog.distantreader.org:2100/biblios? version=2.0& operation=searchRetrieve& query=love& maximumRecords=4& recordSchema=marcxml
I was very impressed with this functionality, but two things were lacking. The first and most important was support of faceted results. I wanted to group my results by author, collection, data type, etc., and the out-of-the-box interface did not support this. After shaking the bushes, per se, a person named Andreas Roussos voluntarily stepped up and wrote a patch to Koha's SRU implementation for me. I applied the patch and the faceting worked seamlessly. "Thank you, Andreas!" I can now facet the previous query:
http://catalog.distantreader.org:2100/biblios? version=2.0& operation=searchRetrieve& query=love& maximumRecords=4& recordSchema=marcxml& facetLimit=32
The second thing lacking was robust support of XSL stylesheets. Raw SRU/XML streams makes things easier for computer post-processing but makes things difficult for people. XSL stylesheets are intended to overcome this problem by transforming the SRU/XML into HTML and then rendering it in a Web browser. The Koha SRU allows for stylesheets, but there was no place to save them without the Koha user interface getting in the way. And while one is able to denote the location of a stylesheet on a different computer, one's Web browser will complain because the risks of CORS (cross-origin resource sharing). Again, after shaking the bushes a bit, I learned of a Web server (Apache) configuration called ProxyPass. Using this configuration in an Apache virtual host definition, I was able to denote a simplified name for the SRU interface, map the name to the canonical host/port combination, and specify the location of any stylesheets. The whole thing was extraordinarily elegant:
<VirtualHost index.distantreader.org:80 >
ServerAdmin [email protected]
DocumentRoot /var/www/index
ServerName index.distantreader.org
ProxyPass "/style-searchRetrieve.xsl" "!"
ProxyPass "/style-explain.xsl" "!"
ProxyPass / http://catalog.distantreader.org:2100/
</VirtualHost>
I can now search, retrieve, and render a query:
http://index.distantreader.org/biblios? version=2.0& operation=searchRetrieve& query=love& maximumRecords=4& recordSchema=marcxml& facetLimit=32& stylesheet=style-searchRetrieve.xsl
While the ProxyPass configuration is essential, the stylesheets make the whole thing come to life. There are two of them: 1) explain to HTML, and 2) search/retrieve to HTML.
But wait. There's more!
Like any library catalog or bibliographic index, one can do the perfect search and get back dozens, if not hundreds or thousands, of relevant search results. Don't let them fool you. Yes, those items at the top of the list are the most statistically relevant, but the differences between the relevancy ranking scores are tiny; for all intents and purposes each item is equally relevancy ranked. Consequently, one is left with the problems of getting the articles, reading them, and coming to an understanding of what they say.
To address this problem -- the problem of consuming a large corpus of materials -- the Index sports a function labeled "Automatically build a data set". Here's how it works:
- enter a simple query - a single word or quoted phrase
- use the faceted search results to refine the query
- when you are satisfied with the results, click "Automatically build a data set"
You will then be asked to authenticate against ORCID. If successful, a data set will be created from the search results, and one can apply natural language processing, machine learning, generative-AI, and general text and data mining to the collection. Heck, one can even print the items in the collection and consume them in the traditional manner of reading. No click, save, click, save, click, save, click, save, etc.
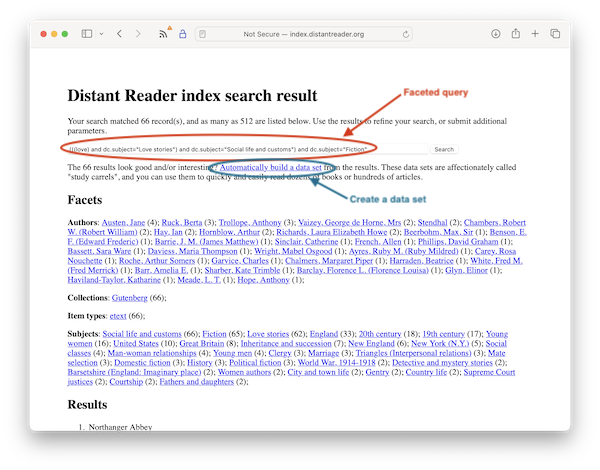
Screen shot of the the Distant Reader Index
Summary
Koha is a first-class citizen when it comes to open source software, especially in the library domain. Feed it MARC records, the records get indexed, and the search interface is more than functional. Additionally, one can turn on both OAI-PMH and SRU interfaces making a Koha catalog's content machine readable. With the help of the community, I have done this work, and I have taken it one step further. Not only can one search the collection and get results, but one can also create a data set from the results for the purposes of reading at scale.
Creator: Eric Lease Morgan <[email protected]>
Source: This is the first publication of this posting.
Date created: 2024-06-19
Date updated: 2024-06-19
Subject(s): Distant Reader; Koha; SRU (Search Retrieve via URL);
URL: https://distantreader.org/blog/reader-index/