Using OpenRefine to Remove Duplicates
tl;dnr - Through the use of OpenRefine, one can create more useful HathiTrust collection files.
Introduction
I often take advantage of the HathiTrust and its very large collection of public domain documents, but when I search the collection for just about anything, I am often faced with numersous duplicate items. Because the volume of search results is so large, filtering duplicates is often tedious, but I have learned how to take advantage of OpenRefine's clustering functions to quickly and easily remove duplicates. This blog posting describes how.
The Problem
For simplicity's sake, let's use a HathiTrust featured collection as an example, specificaly, the Adventure Novels: G.A. Henty. [1] At first blush, the collection includes 47 items, but after downloading the collection file, importing it into any spreadsheet application, and sorting/grouping it by title one can see there are dupicate items, for example but not limited to:
- A Knight of the White Cross (two listings)
- Bonnie Prince Charlie (three listings)
- In the Reign of Terror (seven listings)
While manually looping through 47 items and removing duplicates is not onerous, the problem becomes acute when the student, researcher, or scholar tries to create a complete and authoritative list of all Henty's titles; an author search for Henty and filtered by langauge, place of publication, and even specific library returns many copies of the same things. The tedious process of manually removing duplicates from any sizable collection will significantly impede anybody from doing research on whole collections, and it will cause any computer-based analysis to be whoefully inaccrate. This, in turn, will encourage some people to disregard computer-based analysis. From my point of view, such is undesireable, and this is where OpenRefine comes to the rescue.
OpenRefine, the solution
OpenRefine bills itself as "a powerful free, open source tool for working with messy data: cleaning it; transforming it from one format into another; and extending it with web services and external data", and from my point of view, it most certainly lives up to its description. [2] Some of my research would be a whole lot more difficult if it weren't for OpenRefine.
With the idea of removing duplicates and creating a more useful HathiTrust collection file, the first step is to create an OpenRefine project and choose the given collection file as input. [3] Since OpenRefine eats delimited files (like comma-separated value files and tab-separated value -- TSV -- files) for lunch, OpenRefine will recognize the collection file as a TSV file and present you with additional parsing options. In this case, you can accept the defaults and finish initializing the project by clicking the "Create project" button
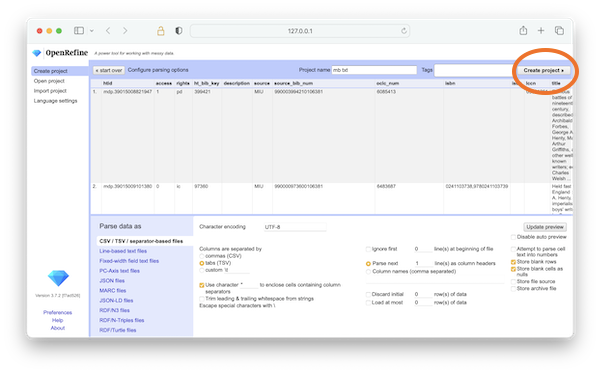
create a project
The next step is to apply text faceting against the title column and sorting the result by count. You will see that a number of items are listed numerous times, and upon closer inspection, you will see some titles with very similar manifestations (differences in cataloging practice). These are the sorts of things we want to both normalize and deduplicate. Click the "Cluster" button.
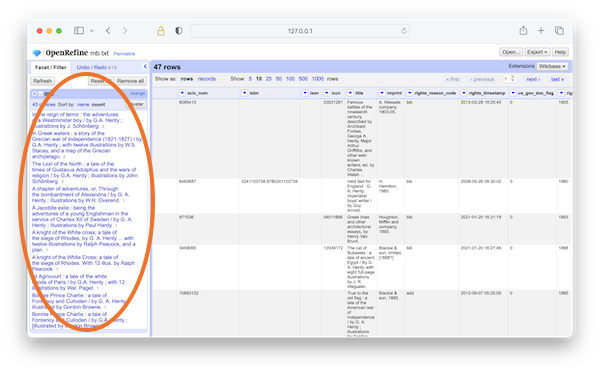
viewing text facets
After clicking the Cluster button you will be presented with a dialog box displaying a large number of clustering options/algorithms. Apply each and every option to the collection, and the titles we become normalized, and when you are finished, the number of items in the collection will not have changed, but the number of unique titles will have decreased; there are now many repeated titles. Click the "Remove all" button to exit the faceting process.
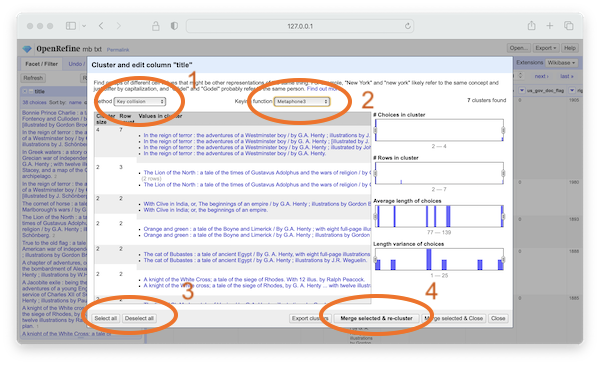
clustering
The next step is pernamently sorting the collection by title, "blanking down", and removing the blanked items. This is the actual process for removing the duplicates. Here's how:
- Sort the titles alphabetically, and then make the sort permanent by selecting "Reorder rows permanently" from the Sort menu.
- Choose "blank down" from the Edit menu, and this retains the first title of many duplicates but makes any subsequent titles empty.
- Text facet on the title columm and select the last value from the facets, and it has the label "(blank)".
- Finally, select "Delete matching rows".
sort titles |
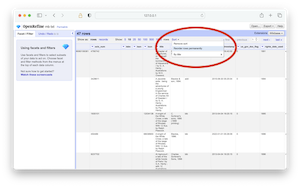
make sort permanent |
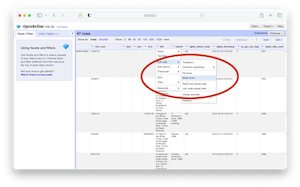
blank down |
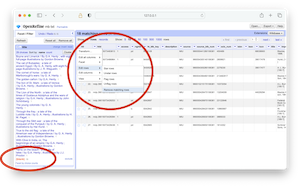
delete matching rows |
If you have been using the Henty collection, then your collection has been reduced to 29 items, and none of the titles are duplicated. Use the "Export" button to save your good work to a file and use the file for further analysis. For example, upload the new file to the HathiTrust Research Center and do processing against it. [4]
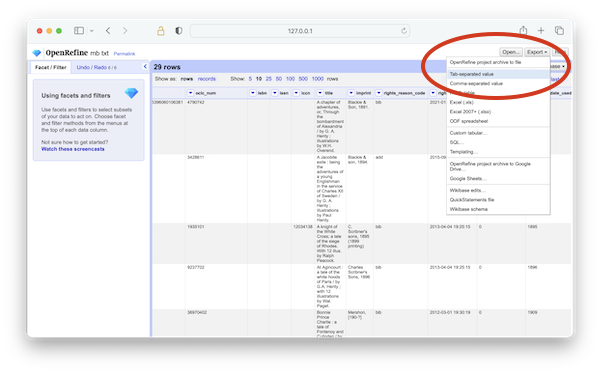
export final result
Extra credit
For extra credit, you might want to apply other cleaning/normalizing processes against the collection file, but removing duplicates is probably the most important. Some of these other processes include making sure the access column includes a value of "1". Otherwise, you may not be able to download the full text of the associated item. You might also want to take a look at the rights_date_used column and make sure there are no dates similar to "9999". You might also want to remove leading articles from the titles so sorted titles... sort correctly.
Summary
The 'Trust is a leading provider of digitized books distributed in the public domain. Using the 'Trust the student, researcher, or scholar can study entire genres or all the complete works written by a given author, but removing duplicates is critical to such analysis. This posting outlined one way to do this with the help of OpenRefine's clustering functions. The OpenRefine website outlines how to use clustering in greater detail. See the website as well. [5]
Links and notes
- Adventure Novels - https://babel.hathitrust.org/cgi/mb?a=listis;c=464226859
- OpenRefine - https://openrefine.org
- Downloading, installing, and launching OpenRefine is an exercise left up to the reader.
- My deduplicated file is linked here.
- clustering - https://openrefine.org/docs/manual/cellediting#cluster-and-edit
Creator: Eric Lease Morgan <[email protected]>
Source: This is the original source of this publication.
Date created: 2023-06-01
Date updated: 2023-06-01
Subject(s): miscellaneous;
URL: https://distantreader.org/blog/removing-duplicates/